이 글은 RNN 기반 컴퓨터 비전에 대한 간략한 소개이다.
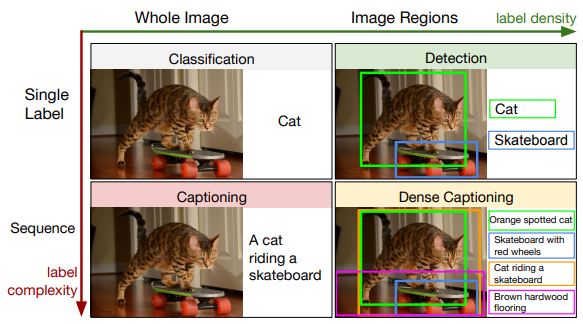
딥 러닝은 일반적으로 전통적인 신경 네트워크, CNN(Convolutional Neural Networks) 및 RNN (Recurrent Neural Networks)의 세 가지 큰 영역으로 나뉜다.
첫 번째는 빅 데이터에서 작동 할 수있는 일반적인 구조이지만 CNN은 이미지에서 작동 할 수 있는 신경망이고 RNN은 텍스트 또는 소리와 같은 시퀀스에서 작동 할 수 있는 신경망이다.

많은 사람들이 CNN을 통한 컴퓨터 비전 또는 RNN을 통한 자연어 처리를 사용한다.
이미지 분류는 CNN을 사용하여 수행 할 수 있다. CNN의 두 번째로 많이 사용되는 응용 프로그램은 객체 감지이다. 이 결과 경계 상자를 나타내는 4개 좌표 목록과 클래스 확률 점수를 출력한다.
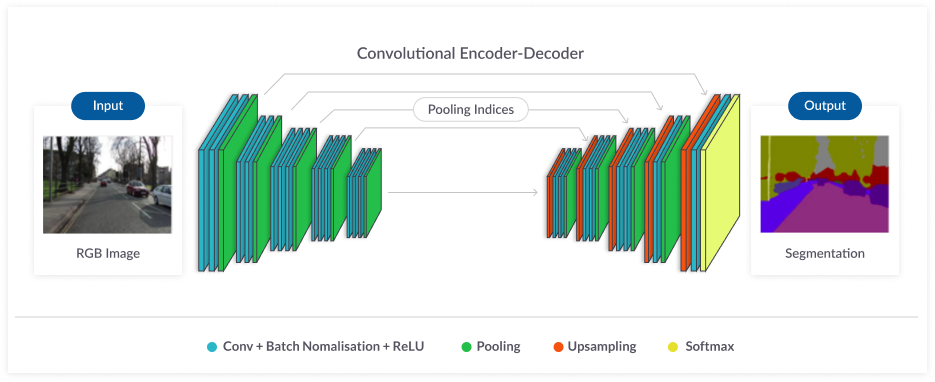
CNN은 이미지 각 픽셀을 분류하고 객체(도로, 보행자, 자동차 등)를 추론할 수 있는 신경망이 생긴다. 세그먼트 이미지를 출력하기 위해 신경망은 두 가지 방식, 즉 인코더와 이미지를 재생성하는 디코더로 작동한다. 전치 된 컨볼 루션과 같은 기법을 사용하여 이미지를 재현한다.
Recurrent Neural Network는 시퀀스와 시간을 이해할 수 있도록 모델링될 수 있다.
비디오 시퀀스 작업을 하는 경우 비디오를 이미지로 분할하고 각 이미지를 독립적으로 처리한다. Recurrent Neural Network에서 시퀀스는 일련의 시간 관련 데이터로 활용된다.
CNN으로 일련의 단어를 가져올 수 있으면, 신경망에 공급하여 클래스를 출력 할 수 있다. 예를 들어 영화 리뷰를 분석하고 텍스트를 positive 또는 negative 로 분류 할 수 있다. 이는 Many-To-One 예측로 불린다.단어의 의미를 이해하고 처음 몇 단어에서 문장의 나머지 부분을 예측하려면 다 대다 예측이 가능해야 한다. 많은 단어를 입력으로 간주하고 각 단어 다음에 모든 선행 단어를 고려하여 다음 단어를 예측한다.

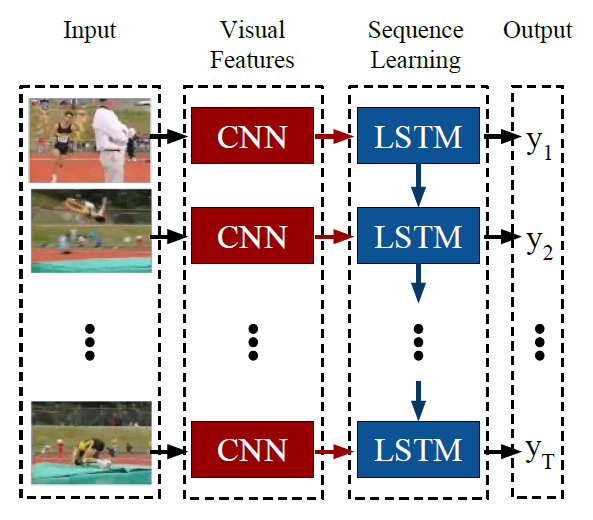
RNN과 CNN을 함께 사용하는 것이 가능하며 실제로는 컴퓨터 비전을 가장 많이 사용하는 것이 될 수 있다. 액션 분류, 영화 생성에 이미 사용되고 있는 기술이다.




댓글 없음:
댓글 쓰기